
R语言基础框架
1.数据类型

2.基本操作
| 函数名 | 作用 | 示例 |
| summary() | 返回描述型统计量,类似describe() | summary(iris) |
| summaryBy() | 根据公式将数据分组并计算描述性统计量 | |
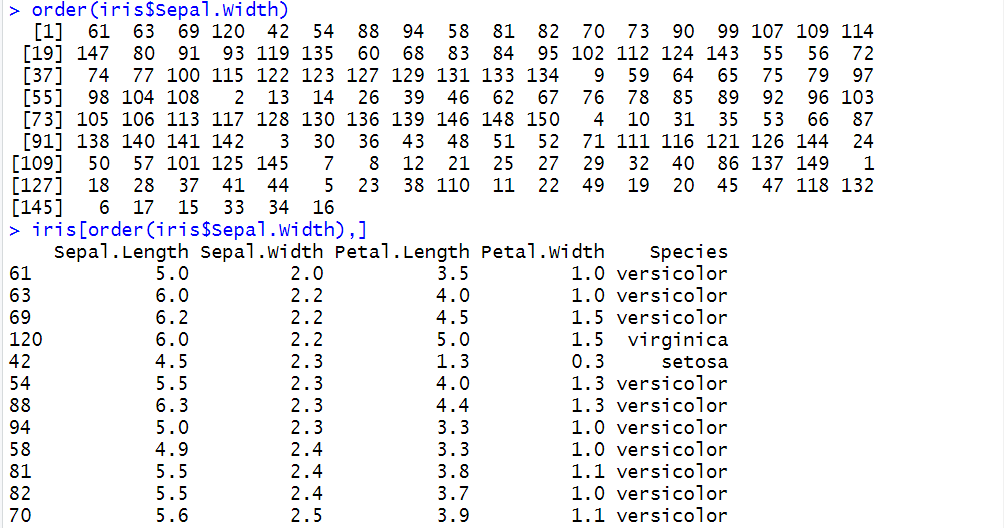
| order() | 返回对数据排序后各数据的原索引 | |
| sample() | 数据抽样 | |
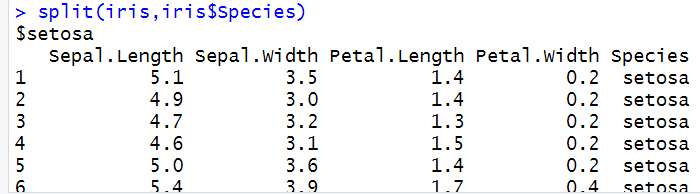
| split() | 根据指定的条件拆分数据 | |
| subset() | 选择满足给定条件的数据 | |
| merge() | 基于共同值合并数据 | |
| stack(x) | 返回值为数据框,values值保存着x合并后的值,ind中保存着因子,指观测值出现的位置 | |
log(x,base=exp(1)求logbase(x)

| 列名 | 含义 | 数据类型 |
| Species | 鸢尾花品种,setosa、versicolor、virginica之一 | Factor |
| Sepal.Width | 花萼宽度 | Number |
| Sepal.Length | 花萼长度 | Number |
| Petal.Width | 花瓣宽度 | Number |
| Petal.Length | 花瓣长度 | Number |
| 函数 | 含义 |
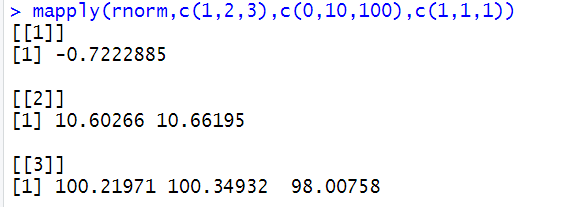
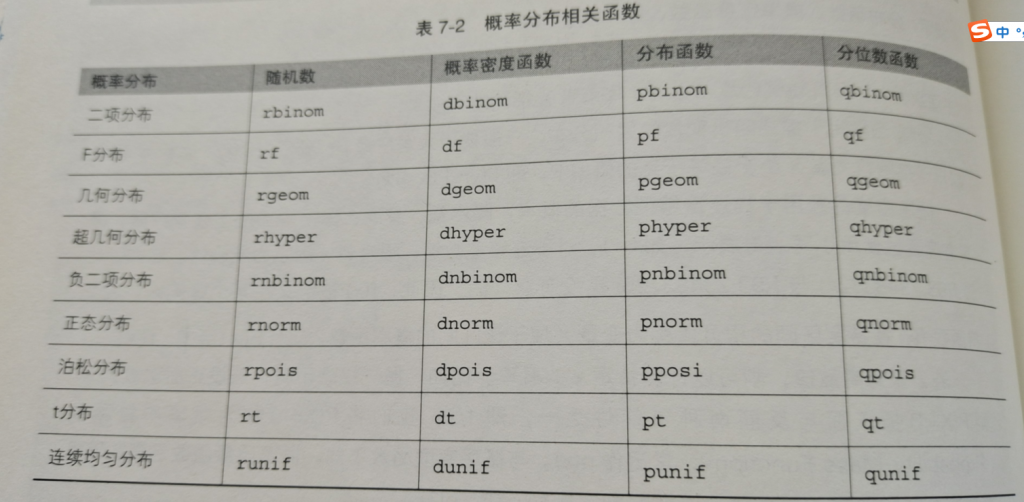
| rnorm(n,mean=0,sd=1) | 生成n个均值为mean,标准差为sd的正太分布随机数 |
| runinf(n,min=0,max=1) | 生成n个均匀分布的随机数,最小值为min,最大值为max |
| rpois(n,lambda) | 生成n个λ为lambda的泊松分布随机数 |
| rexp(n,rate=1) | 产生n个λ为rate的指数分布随机数 |
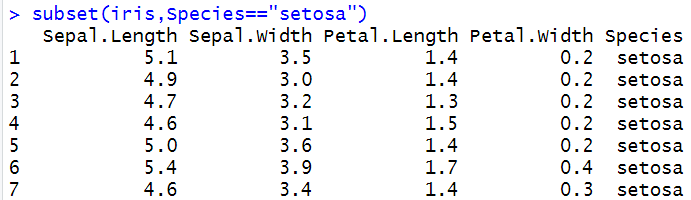
#选择Species=="setosa"&Sepal.Length>5.0的鸢尾花数据 subset(iris,Species=="setosa"&Sepal.Length>5.0) #选择Sepal.Length和Species列 subset(iris,select = c(Sepal.Length,Species))


统计分析
1.生成随机数与分布函数

2.基本统计量
| 统计量 | 函数 |
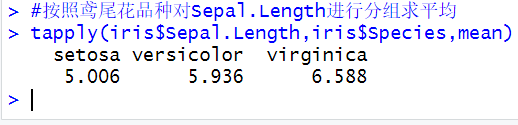
| 样本均值 | mean(x) |
| 样本方差 | var(x) |
| 样本标准差 | sd(x) |
| 众数 | table(x) which.max(table(x)) |
3.样本抽取
| 简单随机抽样 | 不放回抽样sample(1:10,5)放回抽样sample(1:10,5,replace=TRUE) |
| 考虑权值的样本抽取 | sample(1:10,5,replace=TRUE,prob=1:10) |
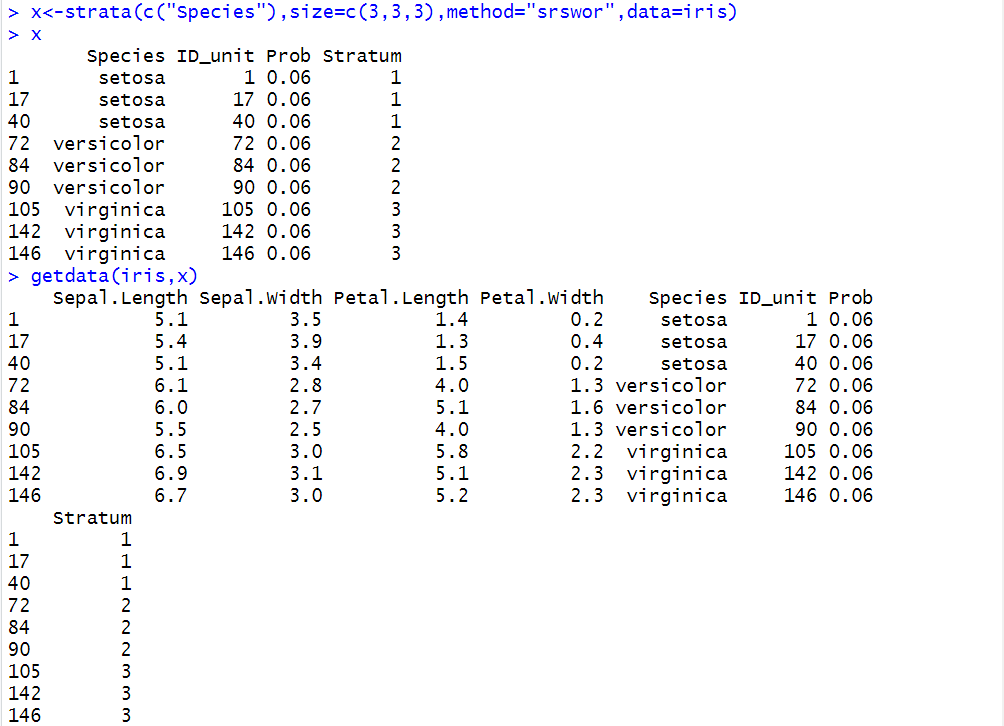
| 分层随机抽样 | x<-strata(c(“Species”),size=c(3,3,3),method=”srswor”,data=iris) getdata(iris,x) |
| 系统抽样 | sanpleBy(~1,frac=.3,data=x,systematic=TRUE) |
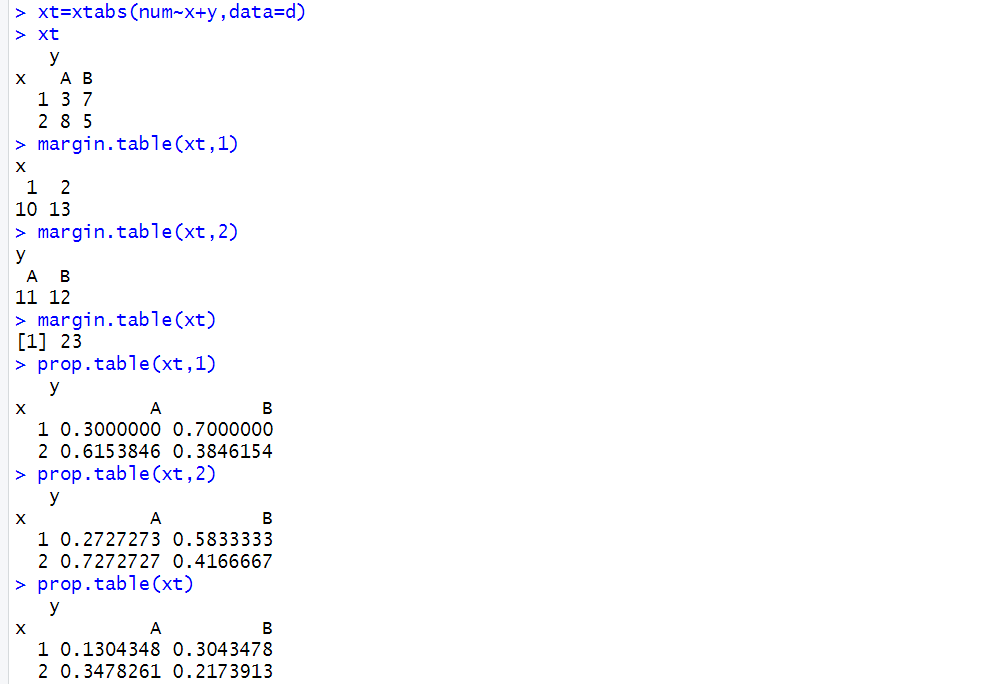
4.列联表分析

library(MASS)
data(survey)
str(survey)
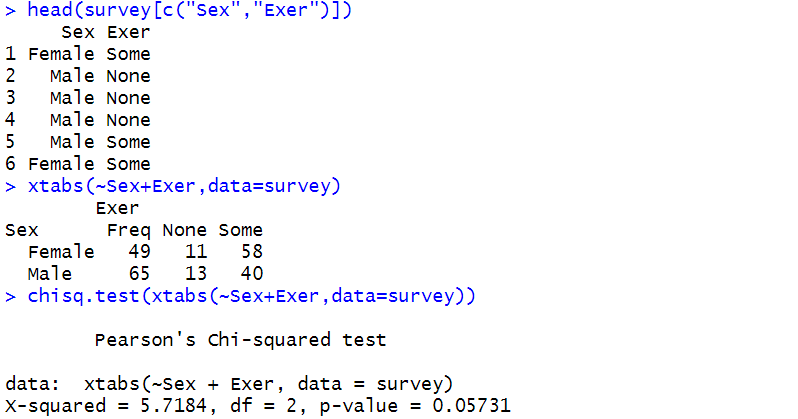
head(survey[c("Sex","Exer")])
xtabs(~Sex+Exer,data=survey)
#独立性检验 卡方检验
chisq.test(xtabs(~Sex+Exer,data=survey))
#费舍尔精确检验
fisher.test(xtabs(~Sex+Exer,data=survey))

5.拟合优度检验

夏皮罗-威尔克检验:用于检验样本是否是从服从正态分布的数据中抽取的。shapiro.test(),零假设一般为:给定的数据样本来自服从正态分布的数据

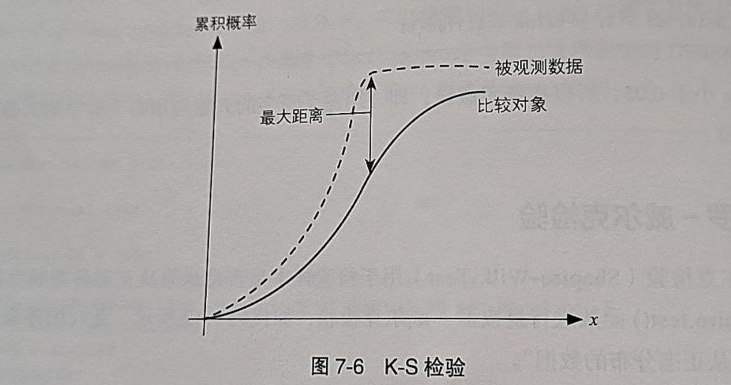
柯尔莫诺夫-斯米尔诺夫检验(K-S检验):将数据的累积分布函数与要比较的分布的累积分布函数之间的最大距离作为统计量。ks.test()
#检验两组服从正态分布的数据之间是否有相同的分布 ks.test(rnorm(100),rnorm(100))

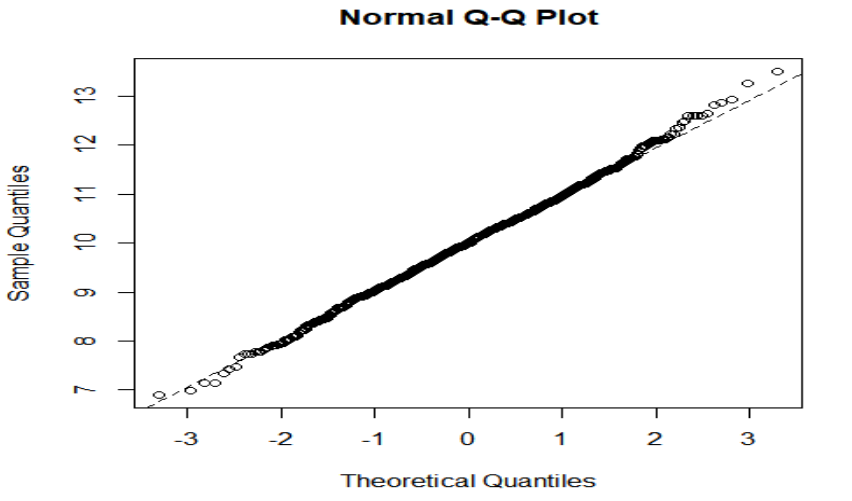
Q-Q图:检验数据是否服从某种特定分布的可视化方法
| qqnorm(y) | 绘制用于比较给定数据与正态概率分布的Q-Q图 |
| qqplot(x,y) | 对两个数据集绘制Q-Q图 |
| qqline(y,distribution=qnorm) | 比较数据与分布,绘制理论上必须成立的直线关系 |
#得到服从N(10,1)正态分布的1000个随机数,然后绘制Q-Q图 x<-rnorm(1000,mean=10,sd=1) qqnorm(x) qqline(x,lty=2)
6.相关分析
#皮尔逊相关系数
install.packages("corrgram")
library(corrgram)
corrgram(iris,upper.panel = panel.conf)

#斯皮尔曼相关系数:不使用两个数据的实际值而使用其等级顺序得到的相关系数取值范围[-1,1]

#肯德尔等级相关系数 cor(m,method = "kendall")
相关系数检验:使用cor.test()进行相关系数检验,以判定相关系数的统计显著性,零假设:H0:相关系数为0;备择假设H1:相关系数不为0
cor.test(x,y,alternative=c(“two.sided”,”less”,”greater”),method=c(“pearson”,”kendall”,”spearman”)
棒棒哒