
文本数据分析
1.语料库jieba、NLTK
NLTK库用来处理英文(英文指定空格为分词标记,调用word_tokenize()函数,基于空格或标点对文本进行分词,并返回单词列表)、jieba库处理中文(只有明显的字句段能通过明显的分解符来进行简单的划分)
2.分词
- 精确分词,试图将句子最精确的切开,适合文本分析
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
- 搜索引擎模式,在精确模式基础上,对长词进行再次切分,提高recall,适合于搜索引擎。
#jieba分词
sentence2="传智专修学院推出颠覆式办学模式"
#全模式划分
terms_list=jieba.cut(sentence2,cut_all=True)
print("Full Mode: " + ", ".join(terms_list))
#精确模式划分
terms_list=jieba.cut(sentence2,cut_all=False)
print("Default Mode:"+",".join(terms_list))
terms_list=jieba.cut(sentence2)
print("默认模式:"+",".join(terms_list))
terms_list=jieba.cut_for_search(sentence2)
print("搜索引擎模式:"+",".join(terms_list))
#加载自定义词典
#jieba.load_userdict("user_dict.txt")#词性标注
words=nltk.word_tokenize(sentence)
nltk.pos_tag(words)
#词性归一化
#导入nltk.stem模块的波特词干提取器
from nltk.stem.porter import PorterStemmer
#按照波特算法提取词干
porter_stem=PorterStemmer()
porter_stem.stem('watched')
#兰卡斯特词干提取器
from nltk.stem.lancaster import LancasterStemmer
lancaster_stem=LancasterStemmer()
lancaster_stem.stem('watched')
#基于WordNetLemmatizer
from nltk.stem import WordNetLemmatizer
wordnet_lem=WordNetLemmatizer()
wordnet_lem.lemmatize('watched',pos='v')from nltk.stem.porter import PorterStemmer
#按照波特算法提取词干
porter_stem=PorterStemmer()
for word in words:
print(porter_stem.stem(word))
#删除停用词
from nltk.corpus import stopwords
stop_words=stopwords.words('english')
#定义一个空列表
remain_words=[]
#如果发现单词不包含在停用词列表中,就保存在remain_words中
for word in words:
if word not in stop_words:
remain_words.append(word)
remain_words
3.英文项目
text_one='This is a wonderful book'
text_two='I like reading this book very much.'
text_thr='This book reads well.'
text_fou='This book is not good.'
text_fiv='This is a very bad book.'
import nltk
#基于WordNetLemmatizer
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
from nltk.classify import NaiveBayesClassifier
def pret_text(text):
#对文本进行分词
words=nltk.word_tokenize(text)
#词性还原
wordnet_lematizer=WordNetLemmatizer()
words=[wordnet_lematizer.lemmatize(word)for word in words]
#删除停用词
remain_word=[word for word in words if word not in stopwords.words('english')]
#True表示该词在文本中
return {word:True for word in remain_words}
#构建训练文本,设定情感分值
train_data=[[pret_text(text_one),1],
[pret_text(text_two),1],
[pret_text(text_thr),1],
[pret_text(text_fou),-1],
[pret_text(text_fiv),-1]]
#训练模型
demo_model=NaiveBayesClassifier.train(train_data)
print(demo_model)
#测试模型
test_text1='I like this movie very much'
demo_model.classify(pret_text(test_text1))
test_text2='The film is very bad'
demo_model.classify(pret_text(test_text2))
test_text3='The film is terrible'
demo_model.classify(pret_text(test_text3))
4淘宝店铺商品评价分析
#爬取商品评价代码
import pandas as pd
import nltk
from nltk.probability import FreqDist,ConditionalFreqDist
import jieba
file_data=pd.read_excel(r'C:\Users\hq\Desktop\商品评价.xlsx')
file_data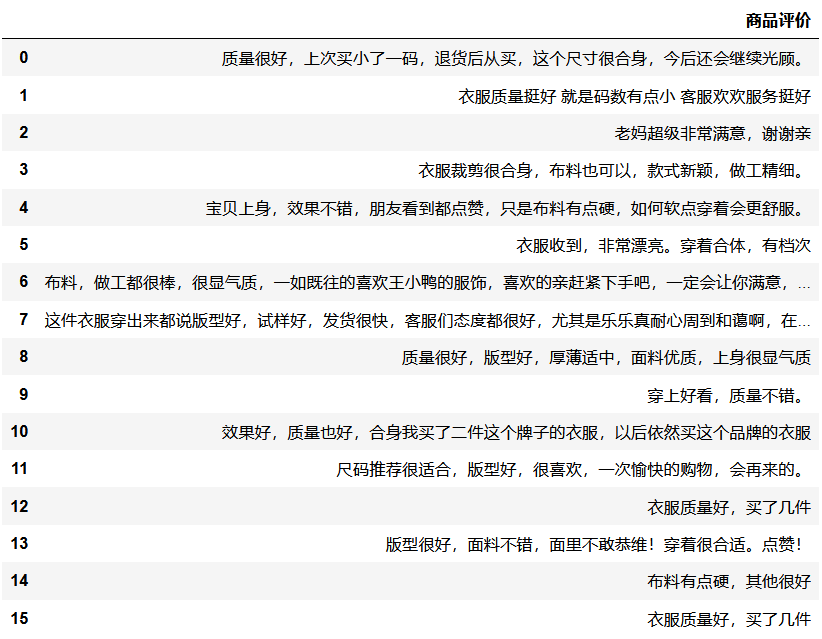
#删除重复评价
file_data=file_data.drop_duplicates()
file_data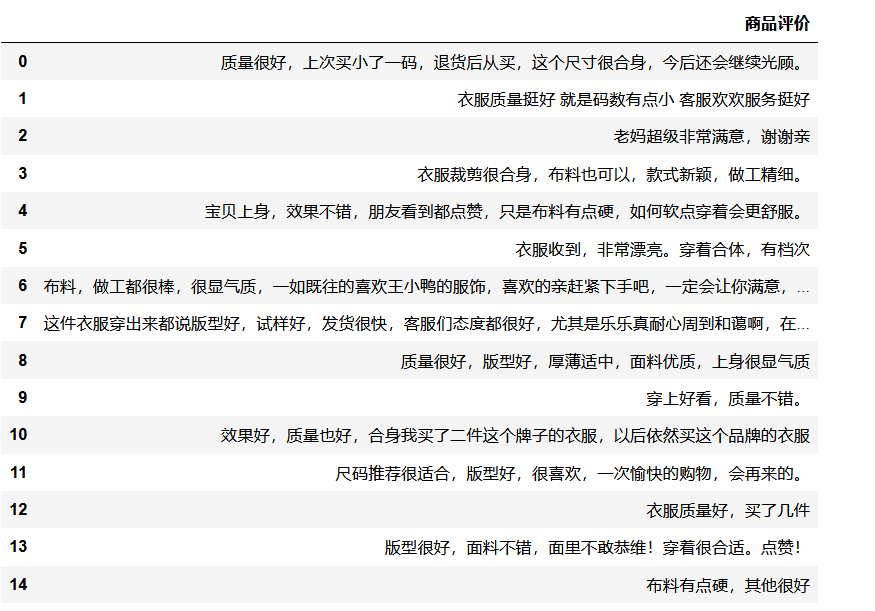
#使用精确模式划分中文句子
cut_words=jieba.lcut(str(file_data['商品评价'].values),cut_all=False)
cut_words
#加载停用词表
file_path=open(r'C:\Users\hq\Desktop\停用词.txt',encoding='utf-8')
stop_words=file_path.read()
new_data=[]
for word in cut_words:
if word not in stop_words:
new_data.append(word)
new_data
#词频统计
freq_list=FreqDist(new_data)
#返回词语列表
most_common_words=freq_list.most_common()
most_common_words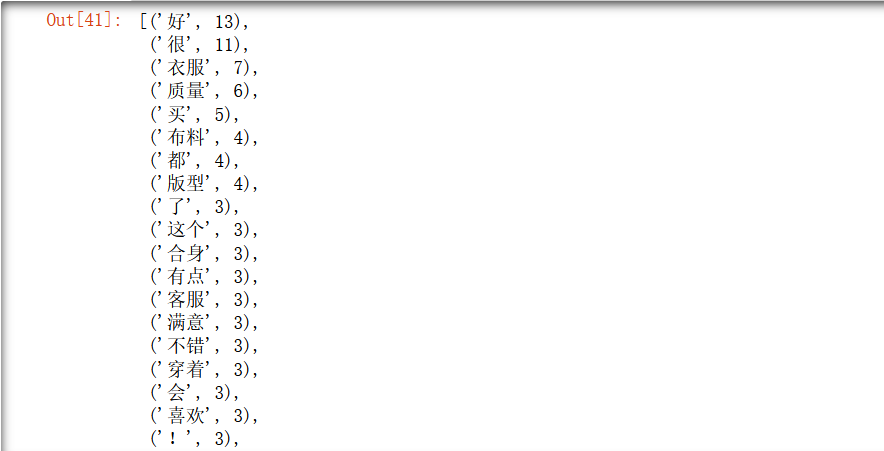
from matplotlib import pyplot as plt
from wordcloud import WordCloud
#词云显示
font=r'C:\Windows\Fonts\STXINGKA.TTF'
wc=WordCloud(font_path=font,background_color='white',width=1000,height=800).generate(" ".join(new_data))
plt.imshow(wc)
plt.axis('off')
plt.show()
近期评论