
数据压缩—导论+通用无损压缩+有损方法
- 指在不丢失有用信息的前提下,缩减数据量以减少存储空间,提高其传输、存储和处理效率,或按照一定的算法进行组织。
结课形式:小论文
参考书:
- 《数据压缩导论》(第四版,Khalid Sayood)
- 《数据压缩》(吴乐南)
信息熵:
\(H(i) = -log_2 (P_i)\)
其中\(P_i\)是发生\(I\)事件的概率
- 统计模型
- 静态/半静态模型
- 自适应模型
- 字典模型
- 静态字典模型
- 自适应字典模型
编码分类
- 熵编码
- 不考虑数据源的无损数据技术
- 源编码
- 考虑信号源的内容,被称为基于语义的编码(有损)
- 混合编码
通用数据压缩方法(无损)
Shannon-Fano编码
- 与huffman编码相反,采用从上到下的方法
- 步骤
- 根据字符集中的字符按照出现频度和频率进行排序
- 用递归的方法分成两类,使得两部分的频率和接近于相等。直至不可再分,即每一个叶子对应一个字符。
- 开始编码
霍夫曼编码
- 步骤
- 概率统计
- 将n个信源信息符号的n个概率,按概率大小排序
- 将n个概率中,最后两个小概率相加,这时概率个数减少为n-1个
- 将n-1个概率按大小排序,继续按照最小两个概率相加
- 重复上述3-4步骤,直至生成树
- 局限性
- 符号的编码长度只能为整数
- 比如有字符出现概率为80%,事实上只需要log_2^0.8位编码,但是一定会分配1个长度
- 输入符号首先与可实现的码表尺寸
- 编码复杂
- 需要事先知道输入符号集的分布
- 符号的编码长度只能为整数
- 变种:范式Huffman编码
- Huffman子集
- 加约束条件,遵守一些规则
- 使用很少的数据便可以重构出编码树,可以有效减少编码字典的存储空间
算术编码
- 相比Huffman编码,其效率有明显提高。对于长序列,理论上算术编码可以达到信源的熵
- 相当于用一个小数,来表示整段数据
- https://zhuanlan.zhihu.com/p/390684936
- 常规的每次都要递推,每次算乘法,资源消耗大
- 可以用自适应方式
- 刚开始各个字符概率相同
- 根据获取到的字符,动态调整编码范围
- 可以用自适应方式
游程编码(Run Length Encoding)
- 思想
- 如果数据项d在输入流中出现n次,则以单个字符对nd替换n次出现者。
- 应用
- RLE文本压缩
- alll -> a@3l
- 存在问题,英文里面很少有大于3的重复字符
- @字符虽然用于提示是压缩的,但是@本身也可能
- 重复计数值以字节形式写在输出流中,单个字节只能计数到255
- alll -> a@3l
- RLE图像压缩
- RLE文本压缩
- 衍生
- 基于字典的压缩方法
- LZ77
- 使用三元组(offset,length,nextChar),固定窗口搜索相同的匹配串
- LZ78
- 相比LZ77,用字典取代LZ77的搜索缓冲器、前向缓冲器、滑动窗口
- 步骤
- 当输入流读入下一个字符时,判断单字符X是否存在
- 存在,则判断下一个y,若能找到则(xpos|ypos,Y)
- 当输入流读入下一个字符时,判断单字符X是否存在
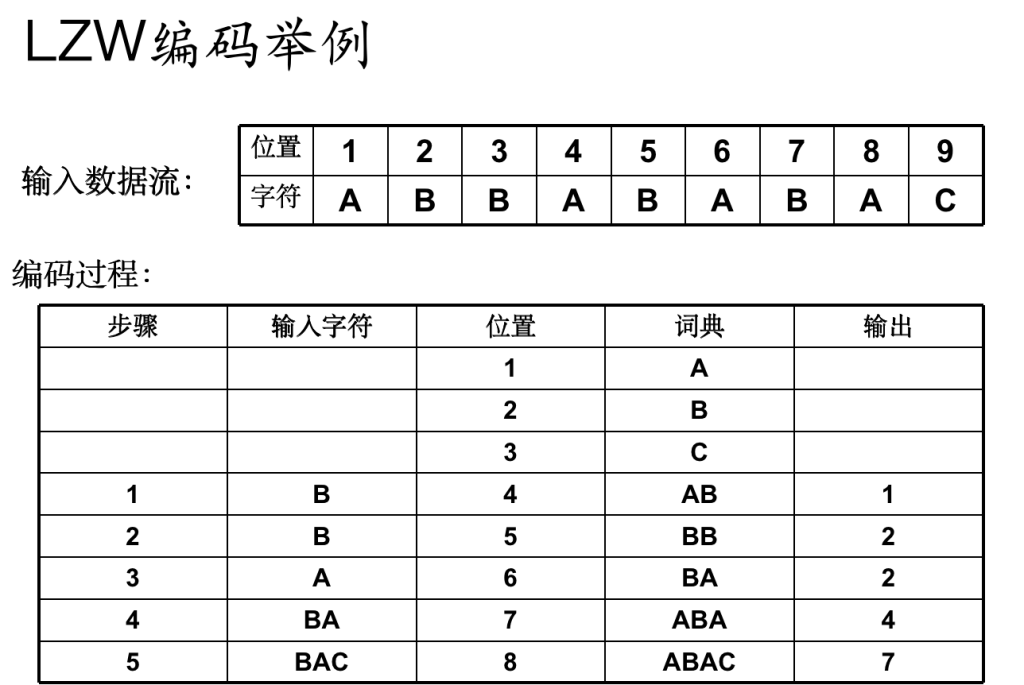
- LZW
- 先统计有多少种单字符,使用编号进行位置初始化
- 每次拿下一个未处理字符与现有字符串进行拼接,若字典内存在,则输出字典的位置,并将将自身定为位置
- LZ77
- 基于字典的压缩方法
Golomb编码
- 主要针对整数进行编码
- 对较小的数用较短的编码,对于较大的数使用较长的编码
- 适合小整数比较多的情况,有效的节省空间

例子,对值x进行编码,可以发现m对编码长度影响很大
| 值 x | m = 0 | m = 1 | m = 2 | m = 3 |
| 1 | 0 | 0 0 | 0 00 | 0 000 |
| 2 | 10 | 0 1 | 0 01 | 0 001 |
| 3 | 110 | 10 0 | 0 10 | 0 010 |
| 4 | 1110 | 10 1 | 0 11 | 0 011 |
| 5 | 11110 | 110 0 | 10 00 | 0 100 |
| 6 | 111110 | 110 1 | 10 01 | 0 101 |
| 7 | 1111110 | 1110 0 | 10 10 | 0 110 |
| 8 | 11111110 | 1110 1 | 10 11 | 0 111 |
| 9 | 111111110 | 11110 0 | 110 00 | 10 000 |
有损方法——DCT变换
- 编码:原图像,DCT变量,除以量化矩阵,取整,压缩图像
- 解码:压缩图像,乘以量化矩阵,DCT逆变换,取整,解压图像
近期评论